2018 January New Microsoft 70-776 Exam Dumps with PDF and VCE Updated Today! Following are some new 70-776 Exam Questions:
1.|2018 New 70-776 Exam Dumps (PDF & VCE) 75Q&As Download:
https://www.braindump2go.com/70-776.html
2.|2018 New 70-776 Exam Questions & Answers Download:
https://drive.google.com/drive/folders/191rIaTzbWdd9hNtirvjRzvhKTjl0Kgbk?usp=sharing
QUESTION 9
You have an on-premises deployment of Active Directory named contoso.com.
You plan to deploy a Microsoft Azure SQL data warehouse. You need to ensure that the data warehouse can be accessed by contoso.com users.
Which two components should you deploy? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Azure AD Privileged Identity Management
B. Azure Information Protection
C. Azure Active Directory
D. Azure AD Connect
E. Cloud App Discovery
F. Azure Active Directory B2C
Answer: CD
QUESTION 10
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on- premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always.
End of repeated scenario.
You need to configure Azure Data Factory to connect to the on-premises SQL Server instance.
What should you do first?
A. Deploy an Azure virtual network gateway.
B. Create a dataset in Azure Data Factory.
C. From Azure Data Factory, define a data gateway.
D. Deploy an Azure local network gateway.
Answer: C
Explanation:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-move-data-between-onprem-and-cloud
QUESTION 11
You have a Microsoft Azure SQL data warehouse.
The following statements are used to define file formats in the data warehouse.
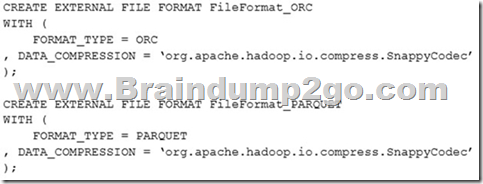
You have an external PolyBase table named file_factPowerMeasurement that uses the FileFormat_ORC file format.
You need to change file_ factPowerMeasurement to use the FileFormat_PARQUET file format.
Which two statements should you execute? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. CREATE EXTERNAL TABLE
B. ALTER TABLE
C. CREATE EXTERNAL TABLE AS SELECT
D. ALTER EXTERNAL DATA SOURCE
E. DROP EXTERNAL TABLE
Answer: AE
QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You change the interval to 24.
Does this meet the goal?
A. Yes
B. No
Answer: B
Explanation:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-create-datasets
QUESTION 13
You plan to deploy a Microsoft Azure virtual machine that will a host data warehouse.
The data warehouse will contain a 10-TB database.
You need to provide the fastest read and writes times for the database.
Which disk configuration should you use?
A. storage pools with mirrored disks
B. RAID 5 volumes
C. spanned volumes
D. stripped volumes
E. storage pools with striped disks
Answer: E
QUESTION 14
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You add a structure property to the dataset.
Does this meet the goal?
A. Yes
B. No
Answer: B
Explanation:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-create-datasets
QUESTION 15
You have a fact table named PowerUsage that has 10 billion rows. PowerUsage contains data about customer power usage during the last 12 months. The usage data is collected every minute. PowerUsage contains the columns configured as shown in the following table.

LocationNumber has a default value of 1. The MinuteOfMonth column contains the relative minute within each month. The value resets at the beginning of each month.
A sample of the fact table data is shown in the following table.
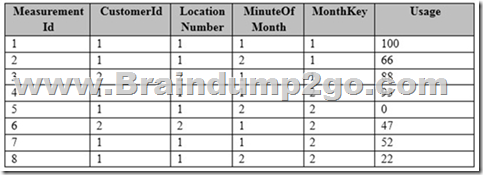
There is a related table named Customer that joins to the PowerUsage table on the CustomerId column. Sixty percent of the rows in PowerUsage are associated to less than 10 percent of the rows in Customer. Most queries do not require the use of the Customer table. Many queries select on a specific month.
You need to minimize how long it takes to find the records for a specific month.
What should you do?
A. Implement partitioning by using the MonthKey column.
Implement hash distribution by using the CustomerId column.
B. Implement partitioning by using the CustomerId column.
Implement hash distribution by using the MonthKey column.
C. Implement partitioning by using the MonthKey column.
Implement hash distribution by using the MeasurementId column.
D. Implement partitioning by using the MinuteOfMonth column.
Implement hash distribution by using the MeasurementId column.
Answer: C
!!!RECOMMEND!!!
1.|2018 New 70-776 Exam Dumps (PDF & VCE) 75Q&As Download:
https://www.braindump2go.com/70-776.html
2.|2018 New 70-776 Study Guide Video:
https://youtu.be/fky71_zJ2qU